MySQL索引及其优化
1.索引的数据结构
哈希索引
哈希索引为索引列计算一个哈希值,然后存放在一个哈希表中。如果哈希值相同,则以链表的形式连接。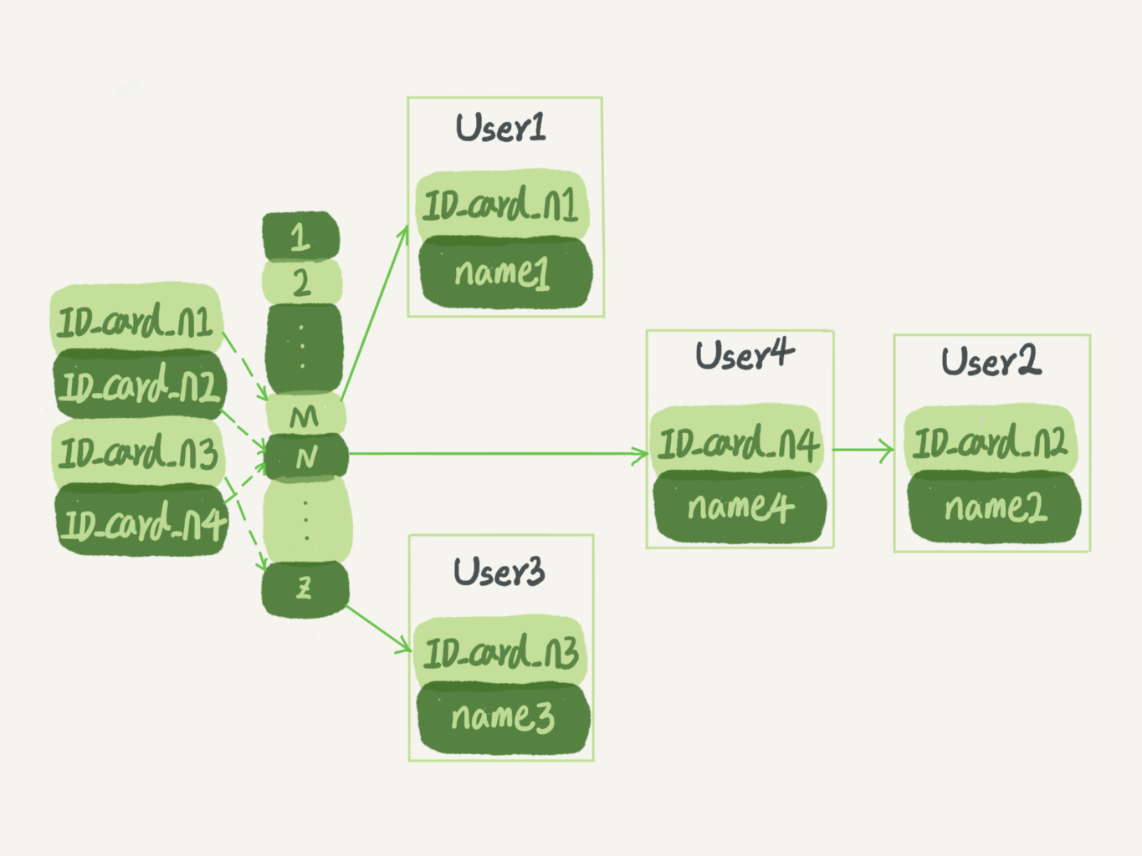
- 哈希索引数据未排序,因此做区间查询的速度慢,且无法用于order by
- 哈希索引对于数据读取特别快,但只适用于等值查询的场景,比如Memory引擎
- 如果哈希冲突很多,索引维护代价高
B-Tree索引
最常用的索引,大多数MySQL引擎支持B-Tree索引(Archive引擎不支持任何索引),虽然名字叫B-Tree索引,但不同的引擎内部有自己的实现方式,比如NDB集群引擎内部使用B-Tree结构存储数据,而InnDB使用B+Tree结构。
InnoDB 索引结构
二叉搜索树是查询效率最高的,但是实际上大多数的数据库存储却并不使用二叉树。其原因是,索引不止存在内存中,还要写到磁盘上。
你可以想象一下一棵100万节点的平衡二叉树,树高20。一次查询可能需要访问20个数据块。在机械硬盘时代,从磁盘随机读一个数据块需要10 ms左右的寻址时间。也就是说,对于一个100万行的表,如果使用二叉树来存储,单独访问一个行可能需要20个10 ms的时间,这个查询可真够慢的。
二分查找每一次搜索就是一次IO,如果想减少IO操作,必须把树变矮,存储数据不变,则每个节点变多,也就是N叉树(B+树的阶)。“N”取决于数据块的大小。
以InnoDB的一个整数字段索引为例,这个N差不多是1200。这棵树高是4的时候,就可以存1200的3次方个值,这已经17亿了。考虑到树根的数据块总是在内存中的,一个10亿行的表上一个整数字段的索引,查找一个值最多只需要访问3次磁盘。其实,树的第二层也有很大概率在内存中,那么访问磁盘的平均次数就更少了。
2.索引的类型
索引按照类型区分
- 普通索引:仅加速查询
- 唯一索引:加速查询 + 列值唯一(可以有null)
- 主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个
- 组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
- 全文索引:对文本的内容进行分词,进行搜索
普通索引和唯一索引如何选择?
当数据页更新时,如果这个数据页还没有在内存中的话,
在不影响数据一致性的前提下,InooDB会将这些更新操作缓存在change buffer中。
当下次访问这个数据页的时候,会将change buffer持久化到磁盘。
记录要更新的目标页在内存中:
- 对于唯一索引来说,找到合适的位置,判断到没有冲突,插入这个值,语句执行结束;
- 对于普通索引来说,找到合适的位置,插入这个值,语句执行结束。
记录要更新的目标页不在内存中:
- 对于唯一索引来说,需要将数据页读入内存,判断到没有冲突,插入这个值,语句执行结束;
- 对于普通索引来说,则是将更新记录在change buffer,语句执行就结束了。
综上,尽量选择普通索引,如果有唯一性需求,在业务代码中做判断。
ps.索引合并,使用多个单列索引组合搜索
3.InnoDB索引模型
主键索引和非主键索引
假设有以下表T,id为主键,k建索引。
1 | |
那么将会对应2颗索引树主键索引和非主键索引,如下图。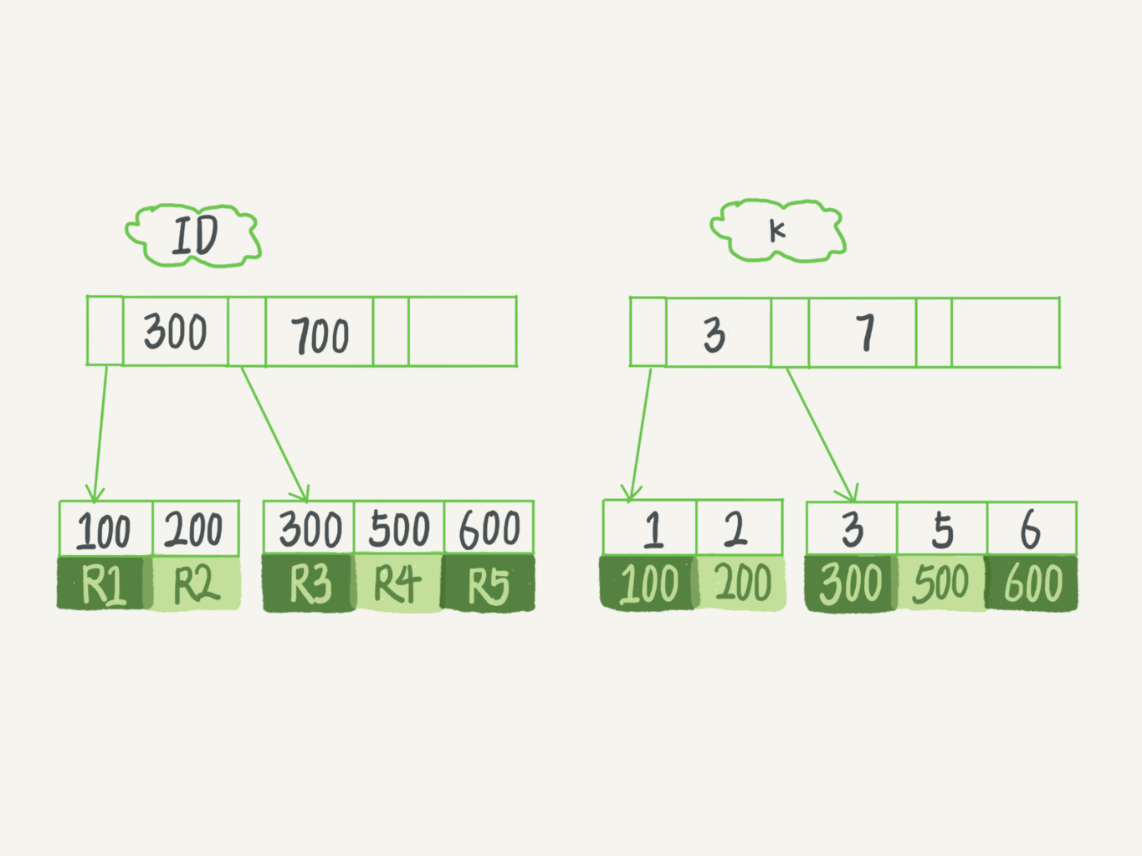
- 主键索引的叶子节点存的是==整行数据==。在InnoDB里,主键索引也被称为==聚簇索引==(clustered index)。
- 非主键索引的叶子节点内容是==主键的值==。在InnoDB里,非主键索引也被称为二级索引(secondary index)。
1 | |
以上两个语句虽然结果是一样的,但是查询过程有差别:
- where ID=500, 主键查询方式,则只需要搜索ID这棵B+树;
- where k=5, 普通索引查询方式,则需要先搜索k索引树,得到ID的值为500,再到ID索引树搜索一次。这个过程称为回表。
基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
对于InnDB,如果建表时候没有指定pk,会判断是否有非空的唯一索引,如果有则该列为主键,如果没有会自动创建一个db_row_id做主键。
主键如何选择
主键可以采用自增也可以以业务字段(比如身份证号)做主键。
- 从性能上看,以业务字段做主键无法保证有序插入,这样使得写数据的成本变高。
- 从存储空间的角度来看,每个非主键索引的叶子节点上都是主键的值,如果用身份证号做主键,那么每个二级索引的叶子节点占用约20个字节,而如果用整型做主键,则只要4个字节,如果是长整型(bigint)则是8个字节。
显然,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
当业务需求,表中只有一个索引,且为唯一索引时,适合使用业务字段做主键。
4.索引优化策略
覆盖索引
上述例子,如果执行的语句是select ID from T where k between 3 and 5,这时只需要查ID的值,而ID的值已经在k索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引k已经“覆盖了”我们的查询需求,我们称为==覆盖索引==。
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
前缀索引
前缀索引就是只给列的前n个字符建立索引。通常适合在大字段上建立前缀索引。
1 | |
n如何选择?
选择性 = 基数 / 记录总数, (1/T ~ 1)
选择性要足够大,唯一索引的选择性为1,是最好的
1 | |
MySQL不支持后缀索引,但是可以采用曲线方式,后缀索引=reverse(前缀)
联合索引
联合索引即在多个字段上建索引,联合索引也符合“最左前缀原则”。
1 | |
如果分别在a、b上建索引,则mysql会采用using intersect交集算法。对所有使用的索引执行同步扫描,并生成从合并索引扫描中接收到的行序列的交集。
联合索引如何排序?

如果通过调整顺序,可以少维护一个索引,则优先考虑该顺序。
如果仅仅只是选择这一个索引,则选择性高的字段排前面。
1 | |
以上sql还是会命中索引,where虽然不符合最左前缀原则,但是id和a字段都在联合索引上,优化器会对比遍历主键索引树和联合索引树的代价,发现联合索引更快,于是会命中。
索引下推
1 | |
MySQL5.6以前是这样走的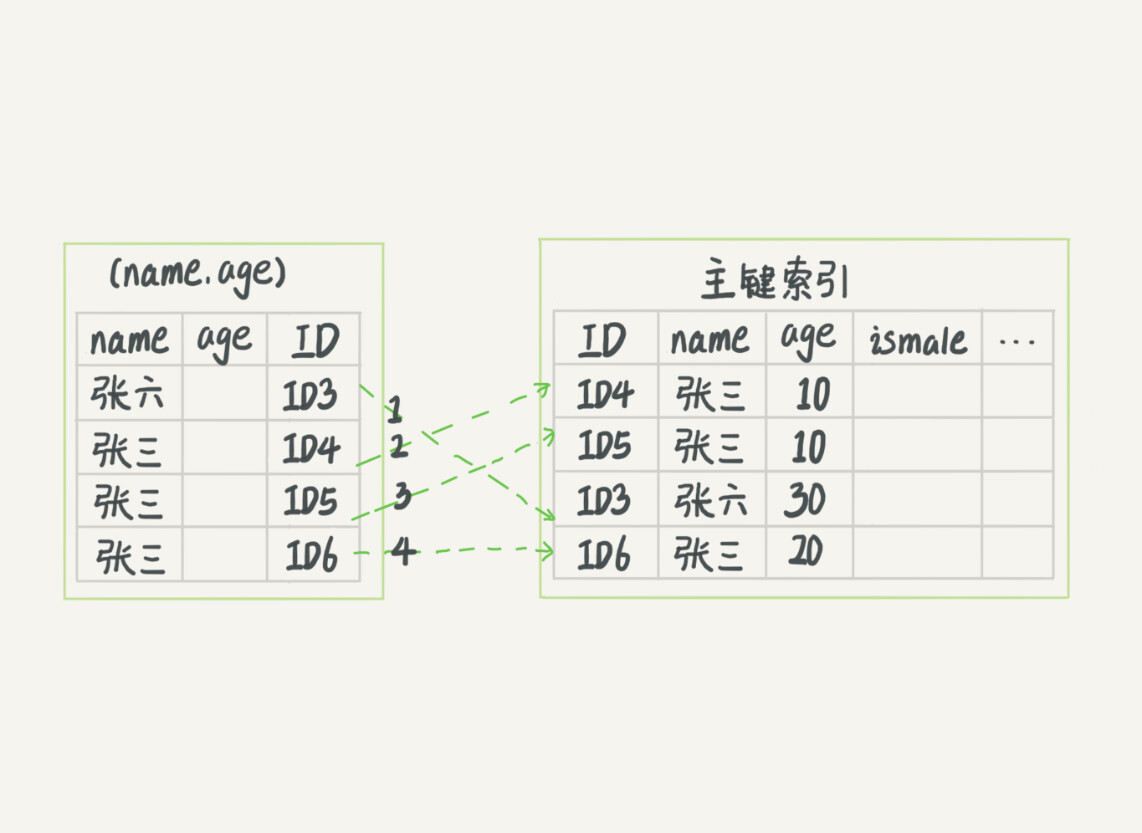
MySQL5.6推出了索引下推策略,是这样走的,减少了回表的次数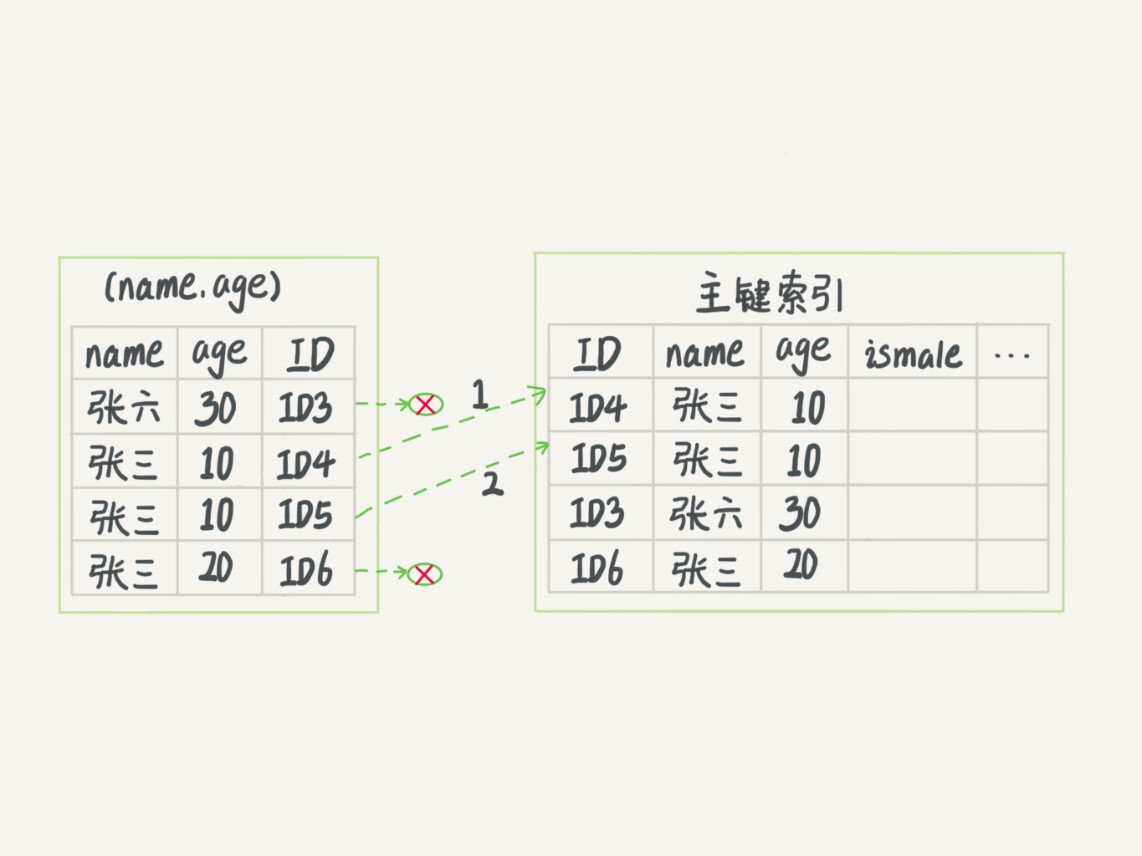
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!